Overview
Starting
with Pega Platform version 8.1, Job Scheduler and Queue Processor rules replace
Agents and improve background processing. Job Scheduler rules replace Advanced
Agents for recurring or scheduled tasks, and Queue Processor rules replace
Standard Agents for queue management and asynchronous processing.
Remark: To mitigate risks and unexpected impacts to customer, however,
product engineering did not convert all default/out of the box Agents to Job
Scheduler and Queue Processor rules. For example, Pega Platform version 8.1.3
ships with 99 Agents, 14 Job Schedulers, and 3 Queue Processors. As another
example, Pega Platform version 8.2.1 ships with 79 Agents, 16 Job Schedulers, and
7 Queue Processors.
Queue Processor
A Queue Processor rule includes two parts: A Kafka topic producer and the
consumer. Queue Processor rule wraps a Stream dataset that under the hood
abstracts a Kafka topic. The underlying Kafka topic is not visible in Pega
Platform. We interact with the Queue Processor rule, and Pega Platform manages
the underlying Kafka topic, from its creation through its deletion.
Queue Processor producer writes to the destination which is a Stream
dataset (producer to Kafka topic) using a smart shape in flow rule or an
activity method. Queue Processor consumer is a real time dataflow that has
Stream dataset as source (consumer of Kafka topic) and executes an activity as
the destination.

Queue
Processor primarily involves below five run time components:
1.
Producer - Publishes messages to a Queue Processor rule. We
can publish messages to a Queue Processor rule using the “Queue-For-Processing”
method in an Activity or using “Run In Background” smart shape from flow
rule.
2.
Stream service - Runs the Kafka broker under the hood. It persists
and replicates the messages we publish to Queue Processor rule (among other
things). More specifically, the Stream service was introduced in Pega Platform
7.4 to provide capabilities such as publishing and subscribing to streams of
data records, storing streams of records, and processing data in real time. As
illustrated in the diagram below, the Stream service is built on the Apache
Kafka platform.
3.
Consumer - Subscribes to messages published to a Queue
Processor rule.
4.
Data Flow Work Object
– In case of Queue Processor, an actual Data Flow rule is not created.
Instead, Pega creates a Data Flow work object which is a representation of an
in-memory Data Flow rule. The source of this in-memory Data Flow is the
consumer (Stream Dataset) which subscribes to the Kafka topic and forwards the
messages to the destination (i.e activity called by the Queue Processor).
5.
AsyncProcessor requestor type -
Provides the context for resolving Queue Processor rules.
Queue Processor rule automatically generates a stream data set and a
corresponding data flow. The stream data set sends messages to and receives
messages from the stream service. The data flow manages the subscription of
messages to ensure message processing. We can view data flows that correspond
with the queue processors in the system on the Queue processors landing page in
Admin Studio.

Queue
Processor Requirements
For the default Queue Processor rules to be active and process
messages, there are three requirements.
Requirement 1 –
AsyncProcessor Requestor Type
The AsyncProcessor Requestor Type was introduced in Pega
Platform version 8.1 to provide the context for resolving Job Scheduler and
Queue Processor rules as those rule types run in the background, and no
user-based context is available to resolve them otherwise. Out of the box, the
default AsyncProcessor requestor type is adequately configured and it is
configured with the application-based access group PRPC:AsyncProcessor.

Remark: It is not uncommon to package a copy of the
AsyncProcessor requestor type with an application that leverages Job Scheduler
and Queue Processor rules. Therefore, it is critical to pay attention when
importing an application packaged with it to ensure that we are not overwriting
it as we could unknowingly disable all Job Scheduler and Queue Processor rules.
Requirement 2 – Node
Types
The default Queue Processor rules are associated with node
types BackgroundProcessing and Search.
Therefore, we must run at least one Pega Platform node that covers those node
types to ensure that all default Queue Processor rules are active and process
messages.
The
details on node classification can be found here:
https://community.pega.com/knowledgebase/articles/performance/node-classification
Requirement 3 – Stream
Service
Ensure that the Stream service is active. For a given node, Pega
Platform starts the Stream service if we classify the node with the type Stream. Naturally, we could classify the node with
additional types as needed.
The
details on Stream Service can be found here:
Putting
It All Together
When considering the Node Types and Stream Service requirements
discussed in the previous section, in Pega Platform version 8.x, there are
three node types at a minimum required to ensure that A) all default Queue
Processor rules are active and process messages and B) the Streaming service is
active. Those node types are BackgroundProcessing, Search, and Stream.
In small development environments, we often leverage a single
Pega Platform node. In such a case, the recommended approach is to specify all
three node types explicitly. From the logical perspective, the three Queue
Processor components are collocated. Although it is rarely the case, we need to
keep in mind that the three components may contend for the same resources when
the node is under load (e.g., CPU, memory). Please note that in this case, best
practices recommend also specifying the WebUser node type.

In an environment where we actively leverage Queue Processor
rules, best practices recommend leveraging a multi-tier deployment
architecture. As an example, consider an application that involves interacting
with users. Furthermore, in this example, assume users create case instances
that publish messages to Queue Processor rules. In such a case, one obvious
option is to architect our deployment with a WebUser tier, a Stream tier, and a
BackgroundProcessing tier.

As illustrated in this diagram, in the context of Queue
Processor rules, the Web tier acts as the producer, the Stream tier provides
the Kafka cluster, and the BackgroundProcessing tier acts as the consumer. What
truly matters in this example is the separation of concerns. Ultimately, this
three-tier deployment architecture enables us to scale up the tiers
independently and also ensures that the different components are not contending
for the same resources when under load.
Pegasystems’ implementation of Kafka does not use
Zookeeper (for reasons beyond the scope of this document). Instead,
Pegasystems’ has implemented a component named Charlatan that acts as a shim
between the Kafka broker and Pega Platform. Furthermore, Charlatan stores the
state information that Zookeeper would normally manage into the Pega Platform
database. The state information includes (but is not limited to) configuration
data, Kafka broker session states, checkpoints, and failed messages. It is
stored in the following tables within the PegaDATA schema:
· pr_data_stream_node_updates
· pr_data_stream_nodes
· pr_data_stream_sessions
As stated before, the Stream service encapsulates and runs
the Kafka broker under the hood. When a Queue Processor rule is created, Pega
internally creates a topic having the same name as the Queue Processor rule in
this Kafka instance. At runtime, when we queue a message to a Queue Processor
rule, the Stream service forwards it to the associated Kafka topic, and in
turn, the Kafka broker persists it to the local filesystem in a directory
named kafka-data. For Apache Tomcat, for example, the kafka-data directory is located by default under the
root of the Tomcat installation (i.e., CATALINA_HOME). Without going into too
many details, you will find a collection of subdirectories within the kafka-data directory for each Queue Processor rule.
The Kafka broker also stores some state information.
In Pega Platform version 8.x, the Stream service is
configured by default with a replication factor of two. More specifically, the
Stream service inherits the replication factor from Apache Kafka. To keep
things simple in the context of this document, think of the replication factor
as the number of nodes where a message is replicated to support
high-availability. For a replication factor of n, for example, there is always
a leader and n-1 followers. The followers serve as hot standby (if you will)
and one will be elected leader if the current leader goes offline. Furthermore,
the Kafka cluster will rebalance itself if a follower goes away, or we add a
new node. As a side note, Cloudera recommended setting the replication factor to at least
three for high availability production systems.
How Queue Processor Works
The Pega
Queue Processor relies on the Stream Service implementation of Kafka. Here is a
high level logical flow and a simple H/A cluster to demonstrate in a general
way how the messages flow through Pega/Kafka and what the different
technologies and roles are.
1.
The Queue Processor is a wrapper around the Stream
Data Set Rule which under the hood encapsulates a Kafka topic. Each wrapper
adds specific functionality and simplifies the interaction for the developer.
2.
The “Queue-For-Processing” Activity
Method or “Run In Background” smart shape sends a clipboard page
to the Standard or Named Dedicated Queue Processor. This represents the
producer part of the Queue Processor.
3.
The Message is sent to the Kafka Broker which saves it
on disk and makes it available to be pulled by a Consumer.
4.
The Stream Data Set also wraps the Kafka Consumer
Functionality, therefore the Queue Processor also supports the consumption of
Messages that have been sent to Kafka. The Queue Processor Wrapper includes
additional capabilities to ensure single transaction processing and guaranteed
delivery.
5.
The Queue Processor consumer part is represented by a
real time DataFlow that has a Stream dataset as source. The Stream dataset
subscribes to the Kafka topic to consume the messages and posts it to the
destination activity of the dataflow which is the activity named in Queue
processor rule for processing of the records.
6.
If the Queue Processor rule is configured for
“Immediate” processing then all the messages posted by the producer are right
away posted to the Kafka topic. The count of such messages posted to Kafka
topic but yet to be consumed by the consumer is represented by “Ready To
Process” column of the Queue Processor landing page in Admin Studio.
7.
If the Queue Processor rule is configured for “Immediate”
processing but is unable to post the messages to Kafka topic due to
unavailability of Stream Service then those messages are saved to the “pr_sys_delayed_queue”
table in the PegaDATA schema instead to avoid loss of messages.
8.
If the Queue Processor rule is configured for “Delayed”
processing then the messages posted by the Producer are saved to the “pr_sys_delayed_queue”
table.
9.
When a message size is too large and exceeds the
maximum message size (configurable via dynamic system settings) then such
messages are saved to “pr_sys_delayed_queue” table. In order to process such large messages
the associated DSS/prconfig entries needs to be updated else the messages will
remain in the delayed table waiting to be processed.
10. The count of messages saved to “pr_sys_delayed_queue” table
and yet to be processed by the Queue Processor is represented by “Scheduled”
column of Queue Processor landing page in Admin Studio.
11. A Job scheduler named “pzDelayedQueueProcessorSchedule” runs
every min to identify the queued records in “pr_sys_delayed_queue” table whose “pztimeforprocessing”
time has expired and moves the such records from “Scheduled” to “Ready
To Process” (i.e reads the records from the table and posts them to the
Kafka topic associated with the Queue Processor rule).
12. A Queue Processor attempts to process the message and in-case of failure
re-tries to process the message again based on “Max Attempt” count configured
on the Queue Processor rule form. The “Max Attempt” for retry also includes the
first attempt to process the message. After the max attempt count is exhausted,
the failed messages are moved to the broken queue which are saved into the “pr_sys_msg_qp_brokenItems”
table in PegaDATA schema. From Pega 8.3 onwards during a retry attempt, the
failed messages are saved to the “pr_sys_delayed_queue” table so
that they can be processed by the next retry. Before Pega 8.3, the retries were
immediate. If “Max Attempt” is set to 1 then the Queue Processor won’t retry
processing and the processing will fail immediately if there is a failure in
first attempt itself. This field can’t be set to 0.
13. The count of messages saved to “pr_sys_msg_qp_brokenItems”
table is represented by “Broken” column of Queue Processor
landing page in Admin Studio. The broken items can be re-processed by requeuing
them in admin studio.
14. A Job scheduler named “pzQueueProcessorMaintenance”runs every
2 minutes to calculate the count of messages “Processed in last hour” shown in
Queue Processor landing page in Admin Studio. This Job scheduler also tries to
restart the Failed Queue Processors.
Figure 1: Queue Processor Logical Flow

Components of a High Availability Queue Processor
·
The
Stream Service manages the Kafka Broker. In figure below, Nodes 4 and 5 are
both stream services which means they both manage a Kafka Broker and
automatically configure the Replication settings. As additional Stream Services
nodes are added, they will manage the growing Kafka Broker Cluster to ensure
appropriate replication and H/A settings
ü
Kafka stores the messages to the file system
·
Kafka Broker is designed to store state information to
Zookeeper, but the stream service uses Charlatan as a shim to translate the
Broker data and command to database tables. This is much simpler and easier for
Pega to manage than zookeeper
·
Stream Data Service can act as both a Publisher to the
Kafka Broker and as a Consumer pulling messages from Kafka. This allows for a
single node to be both Publisher and Consumer or to allow independently scaling
out the number of Nodes Publishing vs Processing
Figure 2: A Pega Cluster with 2 Stream Nodes
for High Availability

Queue Processor rule form decoded
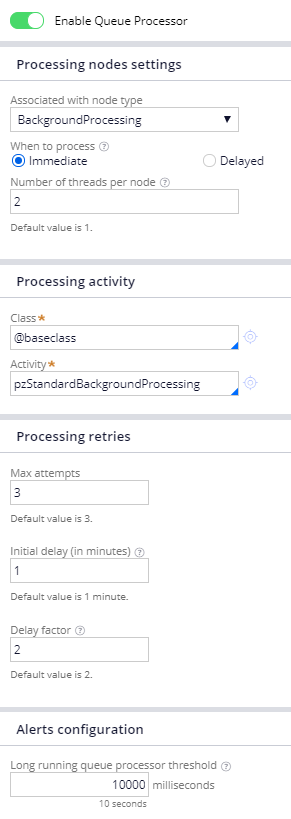
|
Field Name |
Available Field Values |
Meaning of the Field Values |
Default Value |
|
Enable |
i) Enable ii) Disable |
Enable/Disable
the QueueProcessor. Items can still be queued to disabled queueprocessor but
they will not be processed. |
Enabled |
|
Associated
with node types |
List
of available node classifications |
Runs on the selected node type. Option to choose a single
nodetype/ |
BackgroundProcessing |
|
Class |
Drop
down to choose the class |
Represents
the class of the message being queued |
|
|
Activity |
Drop
down to select the activity |
The
activity that gets executed when the queue item is processed |
|
|
When
to process |
Radio
button to choose between Immediate and delayed |
1) If Immediate is selected, the item that is queued gets
pushed immediately to the queue. 2) If delayed is selected, when the user tries to queue an
item to the queue processor, an option to select the datetime for processing
is presented to the user. The item becomes eligible for processing and gets
pushed to the queue when the datetime criteria is met |
Immediate |
|
Number
of threads per node |
Text field to enter the number
of threads. Max value is 20 |
This field represents the
number of threads per node that need to be spawned for this queue processor
to process the items. In a cluster with more than one
node, the total number of threads across all the nodes on the cluster should
not be more than 20 as that is the maximum parallelism we allow as of now. If
it exceeds 20 other threads will remain idle and will not do any processing. |
1 |
|
Max attempts |
Text
field to enter a numeric value |
Represents
the number of attempts to process the message before it is treated as failed
item and moved to the broken process queue. User can view the list of broken
items for a QP from the Queue Processor landing page and requeue/delete them |
3 |
|
Initial
delay (in minutes) |
Text
field to enter a numeric value |
|
1 |
|
Delay
Factor |
Text
field to enter a numeric value |
The factor by which the initial delay value is multiplied to calculate
the period of time between successive retry attempts. |
2 |
|
Long
running Queue Processor threshold |
Text
field to enter a numeric value |
Configured threshold time for the queue processor activity. If
the activity executes beyond this threshold then Pega0117 ALERT is generated. |
2 Secs |
How to Queue Messages to Queue Processor
The producer part of the Queue Processor queues messages to the topic
associated with the Queue Processor rule. The messages can be queued to the
topic using either “Run in background” smart shape or “Queue-For-Processing”
activity method:
Run in background (Smart Shape):
A smart shape called "Run in background" can be used in the case
designer flow rule to queue an item.
Figure 1: Standard Queue Processor when used in Run in background smart
shape

Figure
2: Dedicated Queue Processor when used in Run in background smart shape

Details on “Run in background” smart shape can be found here
https://community.pega.com/knowledgebase/articles/case-management/84/running-background-process
Queue For Processing (Activity Method):
Figure 1: Queue
For Immediate Processing

Figure 2:
Queue For Delayed Processing

|
Field Name |
Available field values |
Description |
Default value |
|
Type |
Standard/Dedicated |
Standard represents queuing to the
OOTB QueueProcessor called pzStandardQueueProcessor. If user chooses this
option there is no need to create a new QueueProcessor. Dedicated represents queuing to a
custom QueueProcessor. |
Standard |
|
QueueProcessor |
Autocomplete
to select the QueueProcessor |
The name of
the QueueProcessor to queue the messages to |
NA |
|
DateTime for processing |
Option to
choose a datetime property in the class of the step page |
If the user
creates a delayed QueueProcessor, this option lets the user to select the
datetime property which will be used to compute the delay. The property
represents the time after which the item will become eligible for processing. |
NA |
|
Lock using |
PrimaryPage Key
defined on property None |
1)
Primary page: When the item is opened from the DB using the pzInskey
persisted as part of message , it is opened with a lock on pzInskey. 2)
Key defined on property : Using the pzInskey value open
the page from database without locking which will be served as the primary
page for the QP activity. In addition to that, another page with the name
pyLockedPage is opened using the reference key with the lock option 3) Using the pzInskey in the message, page is opened from the
database without a lock. |
Primary Page |
|
Write now |
Yes/No |
The default
option is to not choose the Write Now. The message will be pushed as part of
the next database commit. If Write now is selected, the message is
immediately pushed to the queue and will not be part of any transaction. |
No |
|
Queue current snapshot of
page |
Yes/No |
If
not selected which is the default option and user queues a page which has the
property pzInskey, the message that gets queued will just store the pzInskey
and not the entire page. When the item is picked up from the queue for
processing using the pzInskey the corresponding record is opened from the
database. If
selected, the entire page gets pushed to the queue. And the same page will be
used during the processing of the queue item. This is an advanced option used
for performance optimizations. |
No |
|
Alternate access group |
Drop down
to select a property which has the accessgroup value |
By default
when the user enqueues a message, we capture the accessgroup of the thread
enqueuing the message and use it while processing. If the user wants to
execute the item in context of an access group different from the one who is
queuing, this field can be populated |
Empty |
Standard Queue Processor Rule
Out of box, Pega Infinity provides a Standard and Shared Queue Processor rule instance
named “pzStandardProcessor”. It can be used for standard asynchronous
processing when processing does not require high-throughput or processing
resources can be slightly delayed, and when default and standard queue
behaviors are acceptable. This Queue Processor rule is associated with BackgroundProcessing Node Type.

Starting and stopping a queue processor
When a queue processor rule causes issues, you can
stop the queue processor rule temporarily from Admin Studio.
The issue might be related to an unavailable external service, an
unavailable stream node, or it can be a performance issue. After you fix the
issue, enable the queue processor rule.
1.
In the navigation panel of Admin Studio,
click Resources > Queue processors.
2.
Perform one of the following actions:
·
To disable a queue processor rule, in the State column,
click Stop next to the rule.
·
To enable a queue processor rule, in the State column,
click Start next to the rule.
Pega Admin Studio invokes the activity named
"pzStartStopQueueProcessor" available in class
Data-SystemOperations-QueueProcessor-QueueProcessorInfo to start or stop the
queue processor.
Alternatively, we can also use the following activities in Data-Decision-DDF-RunOptions
class to start, stop, resume or retry the queue processor manually by passing
the ID of the Queue Processor rule as parameter.
1.
If QP is in Stopped or Completed state – pxStartbyId/pxStartRunbyId
2.
If QP is Initializing or In Progress state – pxStopbyId
3.
If QP is in Paused state - pxResumeRunById
4.
If QP is in Failed or 'Completed with failures' state - pxRetryRunById
Tracing a Queue Processor
Trace your queue processor rules runs when the activity
it resolves fails or does not work as expected. You can analyze the results of
tracing to identify and fix the issue with queue processor rules.
1.
In the sidebar menu of Admin Studio, click Resources > Queue
processors.
2.
Click the Actions menu icon next to a
queue processor that you want to trace.
3.
Click Trace.
Note: You can only trace queue processors that are
running.